최근 Deep Seek가 자사의 오픈 소스 추론 모델인 R1을 발표하였습니다. R1은 최신 훈련 전략을 기반으로 하여, 기존의 LLM(대형 언어 모델)과는 다른 새로운 확장 패러다임을 제시하고 있습니다. 이번 블로그 포스트에서는 이러한 추론 모델의 훈련 과정과 그 의미에 대해 깊이 있게 살펴보겠습니다.
1. R1 모델의 훈련 전략
Deep Seek는 R1을 훈련하기 위해 두 가지 주요 단계를 도입했습니다. 첫 번째 단계는 **미세 조정(fine-tuning)**입니다. 이 과정에서는 Deep Seek의 강력한 기본 채팅 모델인 V3를 여러 천 개의 추론 예제로 미세 조정하여 좋은 초기 모델을 만듭니다.
2. 강화 학습을 통한 성능 향상
두 번째 단계는 **강화 학습(reinforcement learning)**입니다. R1은 14만 개의 수학 및 프로그래밍 문제를 통해 강한 추론 능력을 갖추게 되며, 각 문제에 대해 64개의 다양한 해답 샘플을 생성해 이를 분석합니다. 이를 통해 모델이 올바른 답변을 도출할 확률을 조정하여 더욱 적절한 추론 패턴을 발견합니다.
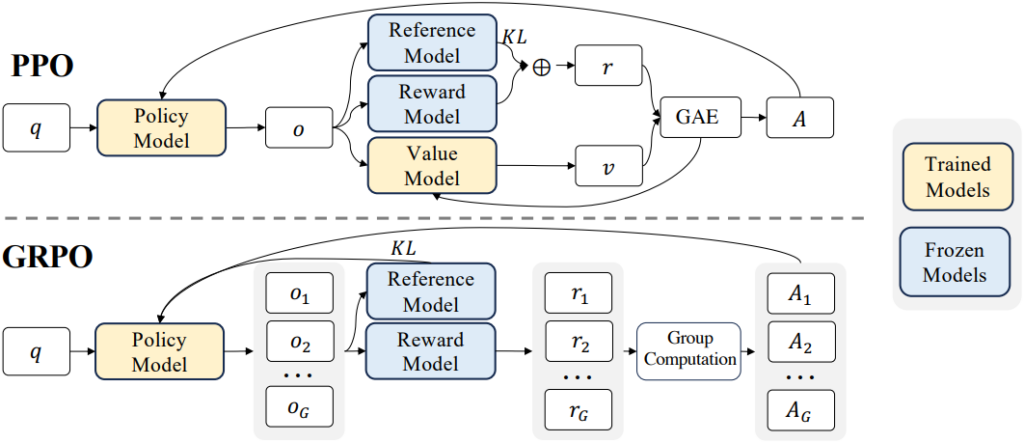
3. 고품질 추론 트레이스 활용
이후 Deep Seek는 첫 번째 단계에서 생성된 60만 개의 고품질 추론 트레이스를 대상으로 두 번째 미세 조정을 진행합니다. 이 과정에서 20만 개의 비추론 데이터가 포함되며, 이는 일반적인 능력을 회복하는 데 도움을 줍니다.
4. R1의 최종 성능
Deep Seek는 R1의 성능을 다양한 벤치마크를 통해 검증하였습니다. R1은 S-bench와 같은 소프트웨어 공학 문제에서 높은 성과를 보이며, 기존의 O1 모델과 비교할 때 경쟁 우위를 점하고 있습니다.
5. 로컬에서 R1 실행하기
R1의 14B 파라미터 모델은 이제 개인의 로컬 환경에서도 실행할 수 있습니다. MacBook Pro와 같은 일반적인 하드웨어에서 실행 가능하며, 사용자는 직접 모델을 시도해 볼 수 있습니다. 이를 통해 Deep Seek는 오픈 소스 생태계에 기여하고 있으며, 사용자가 쉽게 접근할 수 있도록 하고 있습니다.

결론
Deep Seek의 R1 모델은 오픈 소스 추론 모델의 새로운 가능성을 보여주고 있습니다. 이 모델은 독창적인 훈련 전략을 통해 높은 추론 성능을 발휘하며, 사용자가 로컬에서 직접 테스트할 수 있는 기회를 제공합니다. 앞으로 이러한 모델이 더욱 발전하고 개선되기를 기대합니다. Deep Seek에 감사하며, 오픈 소스 커뮤니티의 발전에 기여할 수 있기를 바랍니다.
지금까지 R1 모델에 대한 정보를 알아보았습니다. 이 포스트가 유용했다면 댓글로 의견을 남겨 주세요!