1. 서론: 강화 학습의 가능성
최근 기계 학습 모델의 성과를 향상시키기 위해 대량의 감독 데이터를 이용하는 것이 일반적이었습니다. 그러나 DeepSeek-R1-Zero의 연구 결과는 이러한 전통적인 접근 방식을 넘어서, 감독 데이터 없이도 강화 학습( RL )을 통해 모델의 추론 능력을 크게 향상시킬 수 있음을 보여줍니다. 이 글에서는 DeepSeek-R1-Zero의 훈련 과정에서의 Aha Moment과 성과를 자세히 살펴보겠습니다.
2. Aha Moment의 중요성
2.1 모델의 자가 진화
DeepSeek-R1-Zero는 기본 모델에 대한 RL을 직접 적용하여 시작됩니다. 본 연구는 감독 데이터 없이도 LLM(대규모 언어 모델)이 스스로 추론 능력을 개선할 수 있는 가능성을 제시합니다. 이 과정에서 모델이 스스로의 역량을 인식하고 이를 극대화하는 순간, 즉 Aha Moment가 발생합니다.

2.2 성과 향상 과정
DeepSeek-R1-Zero의 성과는 AIME 2024 벤치마크를 통해 확인할 수 있습니다. 초기 pass@1 점수가 15.6%에서 71.0%로 상승하며, OpenAI-o1-0912 모델과 유사한 성능을 달성했습니다. 이러한 성장은 트레이닝 과정 중 모델이 자신의 학습과정을 이해하고, 점진적으로 개선해 나가는 과정을 통해 이루어졌습니다. 이는 단순한 데이터 학습을 넘어, 모델이 자신의 성장을 스스로 인식할 수 있게끔 하는 능력을 지닌다는 점에서 큰 의의를 갖습니다.
3. 연구 접근법: DeepSeek-R1-Zero의 훈련 과정
3.1 강화 학습 알고리즘: GRPO
본 연구에서 우리는 Group Relative Policy Optimization(GRPO) 알고리즘을 채택하였습니다. 이 알고리즘은 크리틱 모델을 생략하고 그룹 점수로부터 기준선을 추정하여 훈련 비용을 절감합니다. 이는 대량의 데이터를 수집하는 데 드는 시간을 줄일 수 있는 혁신적인 방법입니다. GRPO를 통해 모델은 성과를 극대화하기 위해 최소화해야 하는 목표 함수를 정의합니다.
3.2 보상 모델링
훈련에 있어 보상은 모델의 최적화 방향을 결정하는 중요한 요소입니다. DeepSeek-R1-Zero는 정확도 보상과 형식 보상 두 가지 타입의 규칙 기반 보상 시스템을 채택합니다. 정확도 보상은 모델의 응답이 정답인지 평가하고, 형식 보상은 모델이 자신의 사고 과정을 특정 태그 안에 넣도록 강제하여 일관성을 유지하도록 합니다.
4. 결론: DeepSeek-R1-Zero의 비전
DeepSeek-R1-Zero는 단순히 감독 데이터를 의존하지 않고도 뛰어난 성과를 달성할 수 있음을 보여줍니다. Aha Moment을 통해 모델은 스스로의 역량을 인식하고 이를 기반으로 발전할 수 있는 잠재력을 지니고 있습니다. 이 연구는 향후 LLM의 발전 방향을 제시할 뿐 아니라, 더 나은 AI를 위한 중요한 기초를 마련하는 데 기여할 것입니다.
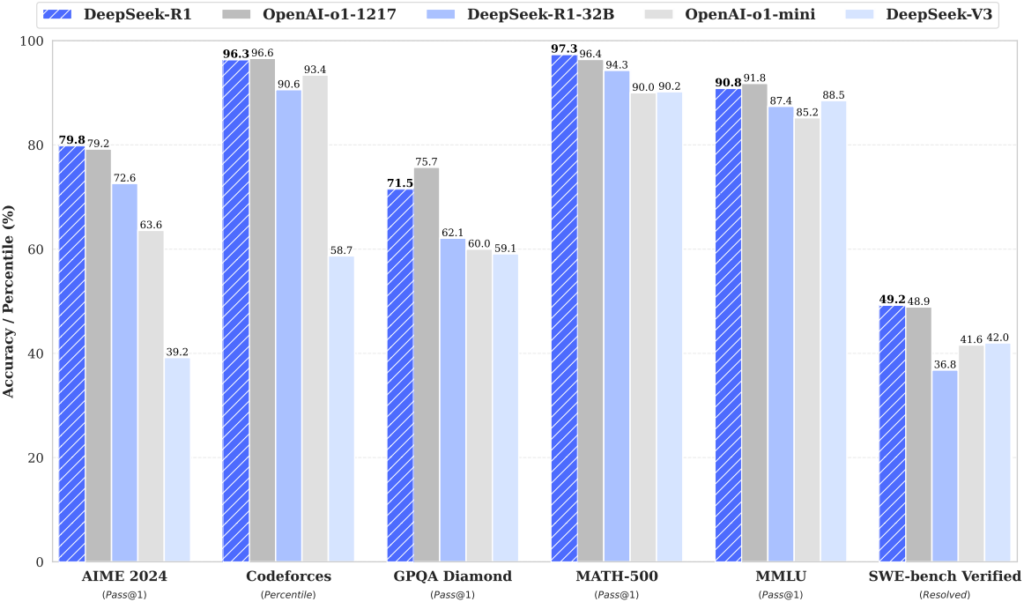
이 논문과 연구는 AI 모델의 진화에 있어 새로운 지평을 여는 계기가 될 것입니다. 앞으로 더 많은 연구가 이 방법론을 바탕으로 진행되기를 기대합니다.