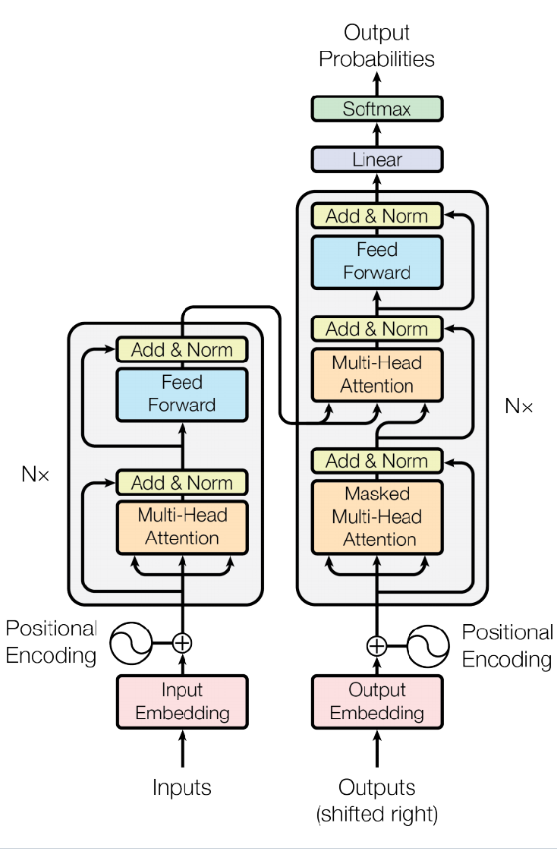
Transformer의 기본 개념
최근 AI 기술이 빠르게 발전하면서, 많은 사람들이 GPT(Generative Pretrained Transformer)에 대해 궁금해하고 있습니다. 이러한 모델은 텍스트를 생성하는 능력으로 주목받고 있으며, 어떻게 작동하는지 이해하는 것은 이 기술의 발전을 이해하는 데 도움이 됩니다. 이번 블로그에서는 transformer의 기본 개념, 작동 원리 및 다음 단어 예측 과정에 대해 자세히 알아보겠습니다.
GPT는 텍스트, 이미지, 오디오 등 다양한 입력 데이터를 처리할 수 있는 transformer 모델 기반입니다. transformer는 2017년 구글에 의해 처음 소개되었으며, 입력된 데이터를 바탕으로 다음에 올 텍스트를 예측하는 데 중점을 두고 설계되었습니다. 이 모델은 문맥을 이해하고 그에 따라 텍스트를 생동감 있게 생성할 수 있습니다.
입력의 토큰화
transformer의 첫 번째 단계는 입력 데이터를 여러 개의 토큰으로 나누는 것입니다. 이 토큰은 단어, 부분 단어 또는 문자 조합을 포함할 수 있으며, 예를 들어 “안녕하세요”라는 단어는 각각의 글자를 토큰으로 만들 수 있습니다. 각 토큰은 벡터로 변환되며, 이 벡터는 해당 토큰이 의미하는 바를 수치적으로 표현합니다. 예를 들어, 비슷한 의미를 가진 단어는 배열된 벡터 공간에서 가까운 위치에 배치됩니다.
주의(Attention) 메커니즘
transformer의 핵심 요소 중 하나는 주의 메커니즘입니다. 이 메커니즘은 각 단어 간의 관계를 이해하고 문맥에 따라 각 단어의 의미를 업데이트하는 데 도움을 줍니다. 예를 들어 “사람이 집에 들어갔다”와 “집에 들어간 사람”에서 ‘사람’의 의미는 문맥에 따라 달라집니다. 주의 메커니즘은 이러한 문맥 정보를 잘 반영하는 데 중요한 역할을 합니다.
입력 토큰 간의 상호작용
토큰 간의 상호작용은 주의 블록을 통해 이루어집니다. 여기서는 각 벡터가 서로 소통하여 정보를 교환하고, 그에 따라 각 벡터가 업데이트됩니다. 이 과정에서 단어의 의미가 문맥에 따라 어떻게 변화하는지를 반영합니다.
멀티레이어 퍼셉트론
토큰 간의 상호작용이 이루어진 후, 벡터들은 멀티레이어 퍼셉트론이라는 또 다른 처리 블록을 거칩니다. 이 단계에서는 벡터들이 특정 연산을 병렬적으로 수행하며, 각 벡터에 대해 독립적으로 처리됩니다. 이 단계는 다음 단어 예측을 위한 중요한 과정입니다.
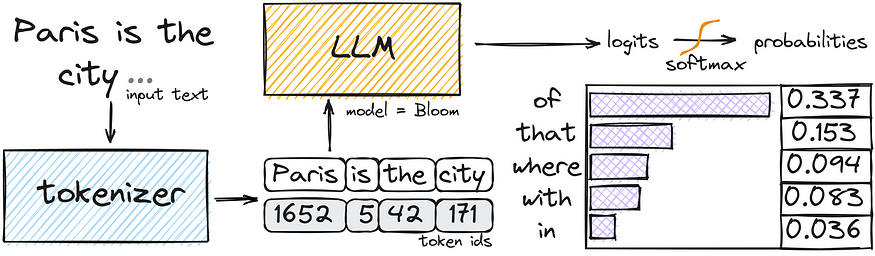
다음 단어 예측
모델이 어떻게 다음 단어를 예측하는지 이해하려면, 각 토큰 벡터가 마지막에 있는 벡터와 결합되어 확률 분포를 생성하는 과정을 살펴봐야 합니다. 예를 들어, 문장에서 마지막 단어가 ‘교수’이고, 문맥에 ‘해리 포터’라는 단어가 포함되어 있다면, 모델은 ‘스네이프’라는 단어가 가장 가능성이 높다고 판단할 수 있습니다.
확률 분포와 샘플링
다음 단어의 예측이 완료되면, 이 예측을 기반으로 무작위로 샘플링을 하여 텍스트를 생성하게 됩니다. 이 과정은 반복적으로 이루어져 긴 텍스트를 생성하는 것이 가능합니다. 샘플링 과정에서는 ‘온도’라고 하는 매개변수를 조정하여 생성되는 텍스트의 다양성과 창의성을 조절할 수 있습니다. 온도가 높으면 더 다양한 단어가 생성될 가능성이 높아지고, 낮으면 더 안전한 선택을 하게 됩니다.
맺음말
이번 포스트에서는 GPT의 기본 원리와 내부 작동 방식에 대해 알아보았습니다. 특히 transformer의 구조, 입력의 토큰화, 주의 메커니즘, 다음 단어 예측 과정에 대해 중심적으로 설명하였습니다. GPT와 같은 모델들이 어떻게 문맥을 이해하고 자연어를 생성하는지에 대한 기초적인 이해가 생겼다면 좋겠습니다.
다음 포스트에서는 주의 메커니즘의 세부 사항과 그 중요성, 그리고 더 깊은 기술적 요소에 대해 다룰 예정입니다. 이 기술이 현재 AI 분야에서 어떻게 활용되고 있는지 더욱 탐구해보겠습니다.
이 글이 유익하셨다면, 댓글로 여러분의 생각을 남겨주세요! AI에 대한 궁금증이나 이야기하고 싶은 주제가 있다면 언제든지 환영합니다.
#GPT
#Transformer
#인공지능
#자연어처리
#주의메커니즘
#텍스트생성
#딥러닝
#기계학습
#다음단어예측
#AI기술